
Bullet proof your technology stack with GraphQL
It has taken a little time for technology like GraphQL to settle in. I find myself in conversations with folks about the use of GraphQL and whether or not it makes sense to use for their project. Maybe GraphQL is good for you, perhaps it is too soon - but by reading this post you should have an idea as to whether or not it is a good time to consider it.
Architecture
This post is from the perspective of an architect. Architects work from the high-level overview of a system rather than the specifics of its parts. GraphQL and orchestration technology is a tool for architects to consider.
Abstraction
Micro-services and component-based architecture teach us that when we build systems and software, keeping things decoupled and somewhat abstracted leaves systems easier to maintain, extend or otherwise replace in parts ( cheaper and incremental ).
One of the most common examples of this type of abstraction in life is the power outlet in a wall. From our perspective, we simply plug the lamp into the wall, but the "how the power gets there" is of no concern to us nor the lamp. As long as the lamp abides by the service level agreement while transacting with the wall socket, it will always behave as expected no matter where in the country we happen to plug it in. Traveling to other countries, however, things get a bit more interesting but for the sake of this example let's leave it at that.
Engineering a system to be dismantled, to be portable and cheaply replaced is an ideal state to be in because upgraded and easy to maintain systems are more secure, reliable and typically performant platforms. For a technology company fast, maintainable and secure systems translate into improved bottom line through reduced labor investment and decreased time to market competitive advantage.
Using abstraction strategically protects larger technology ecosystems from one another. GraphQL, or technology like it, fits in this space by providing means of communication between services using a common language to express data demand while encapsulating away the complexity of understanding where the data is sourced.
GraphQL and orchestration would be the outlet in our lamp example.
But why, why do we need abstraction from services?
Perhaps "why" is not the right question to ask but "when". "When" because the system may be quite simple and not require any abstraction. We see this in the authoring of code all of the time. Engineers need to consider whether or not to use third party code outright or wrap the thing in a way that protects their software from being affected by any change that could occur. In addition, this abstraction would aid in being able to make a different decision in the future while incurring far less technical debt in doing so.
But there are times when it makes no sense to do so. And we need to guard against this. Speaking against adoption for adoption sake.
What about REST
REST has done just a fine job at providing a simple language for software or services to request information from one another. The limitation with REST is that each service that cares to communicate with the other requires that they know the address, the interface of that service and the data it provides. For small semi-trivial systems, REST is just fine. For maturing businesses over time what we find is that services need to iterate to keep up with the increasing demands. Perhaps new features and data need to come about for a new set of features. Maybe testing new sources of information start to become interesting. Or a system is faced with a performance issue it would like to solve by decoupling various processes. This need for iteration on how content is served is critical for a business to stay fast as they work to learn and solve problems.
Though changing and improving services that are communicating with each other is not the problem but it is the connections between services that begin to break down and create complexity. Take for example figure 1:
Figure 1
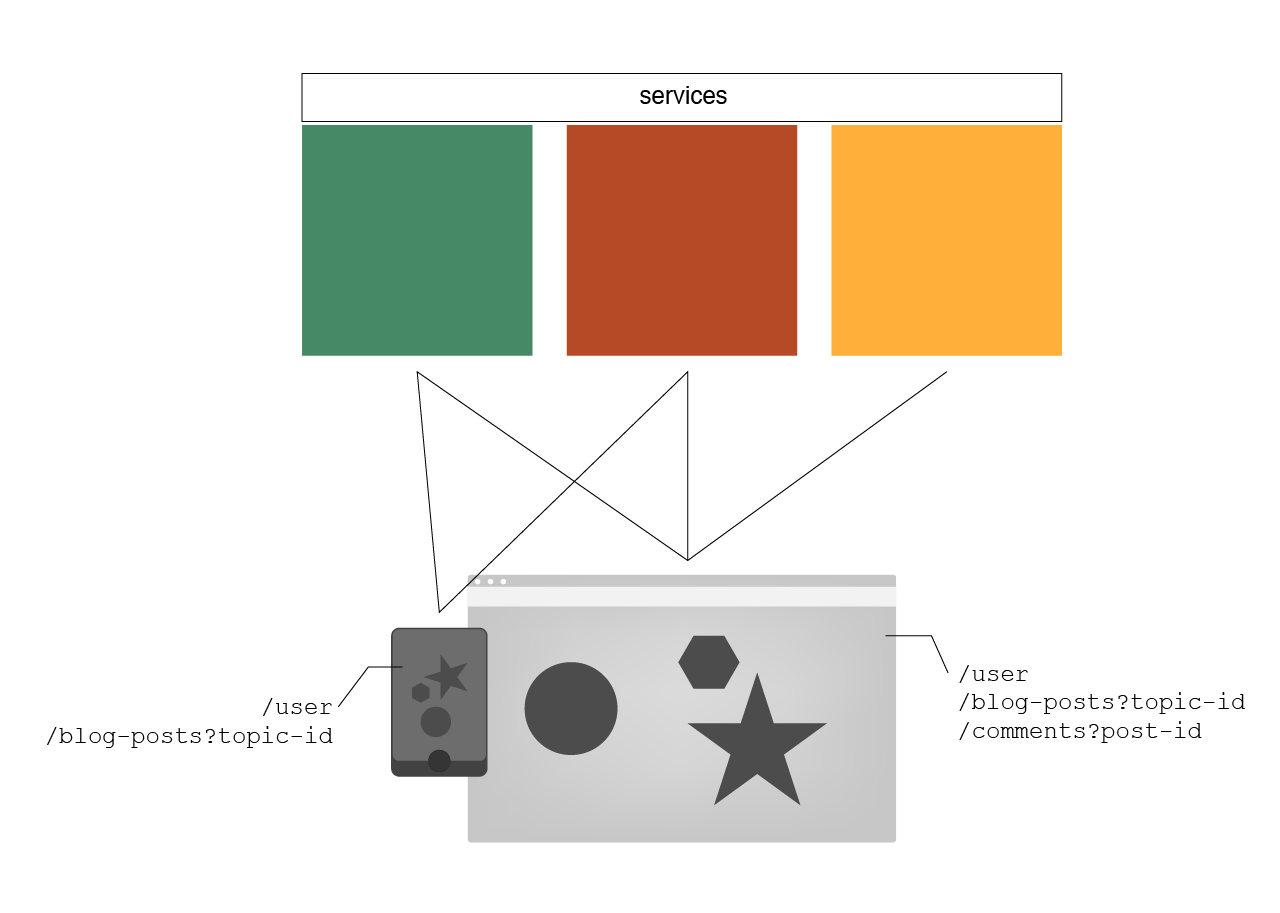
Figure 1 represents the formal pattern of GET'ing content from various RESTful services. There is an underlying complexity that also exists here and that is that each application requesting information also needs to deal with connecting to and aggregating the responses from each service.
The complexity around communicating with services
The problem with any type of communication between services is inconsistency. Considering to connect with any service requires that we also think about these error scenarios in the cases where we may go offline, or if the service for one reason or another becomes unavailable. Engineers need to consider these possibilities for each service or request they are intending to make.
Knowing the when
Earlier I mentioned introducing technology like GraphQL is a question of when - it is perfectly fine to go out and roll your own solution, but it is important to learn how other engineers have solved these problems as well.
When
-
You have multiple clients between services.
-
Have a complex or unorganized data set that could lend itself well to being graphed.
-
Have faced expensive API migrations in your business, or could potentially have the risk of one.
-
You plan to iterate on content sources. For example, for the first quarter, you wish to fetch information about the weather from one source and find out in the second quarter that there is a better source out there that you would like to use instead.
How
So how does technology solutions like GraphQL help us? I am picking on GraphQL a lot in this post because it was the first solution I had seen that had unlocked this type of thinking for me. Though I had considered other options take Netflix's Falcor project for instance, something about representing requests with a query language made sense to me. Without getting too far down the road, the query language allows us to care less about the structure of the source of information and more about the information we actually care about.
Figure 2
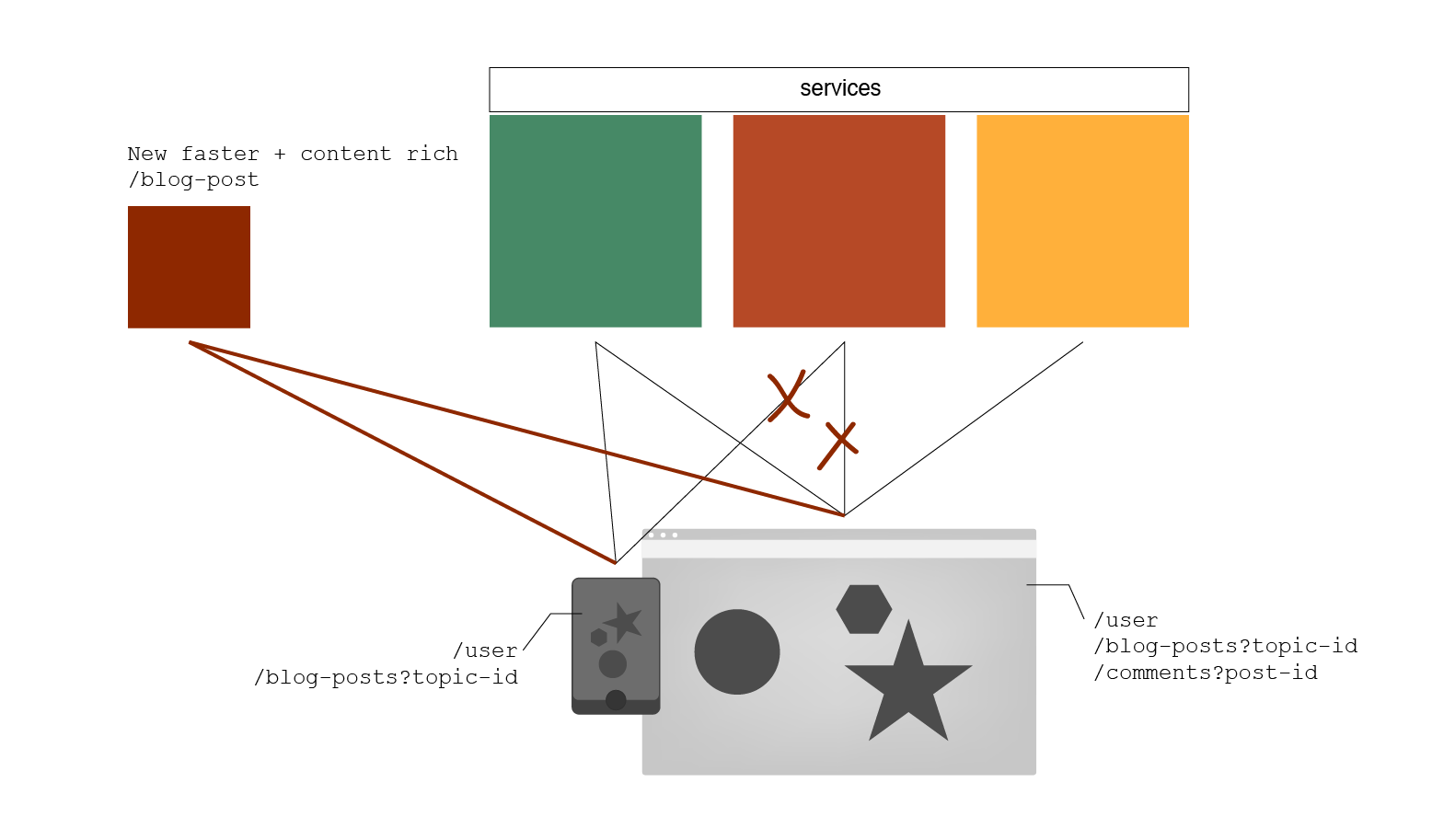
Figure 2 illustrates what tends to happen when a new service comes online with a new address. In this simple example, we show how all connected clients are now responsible for making the appropriate updates to their code, regressing and redeploying to keep the business humming along. What's more is that we now have a service to take down once the connected clients have done their job of migrating away. For larger teams and companies with large suites of software in their arsenal, these changes are difficult and very expensive to get done. I have seen organizations take entire quarters getting this right. In the worst cases, legacy platforms are left behind still calling the older services forcing the company and departments to keep their legacy around for longer than they could have if they had some level of abstraction.
Figure 3

Figure 3 shows us where we can think of libraries like GraphQL sit in our technology stack. GraphQL is a wedge between software. It sits as an interface to connect with various services in a predictable and practical way.
Figure 4
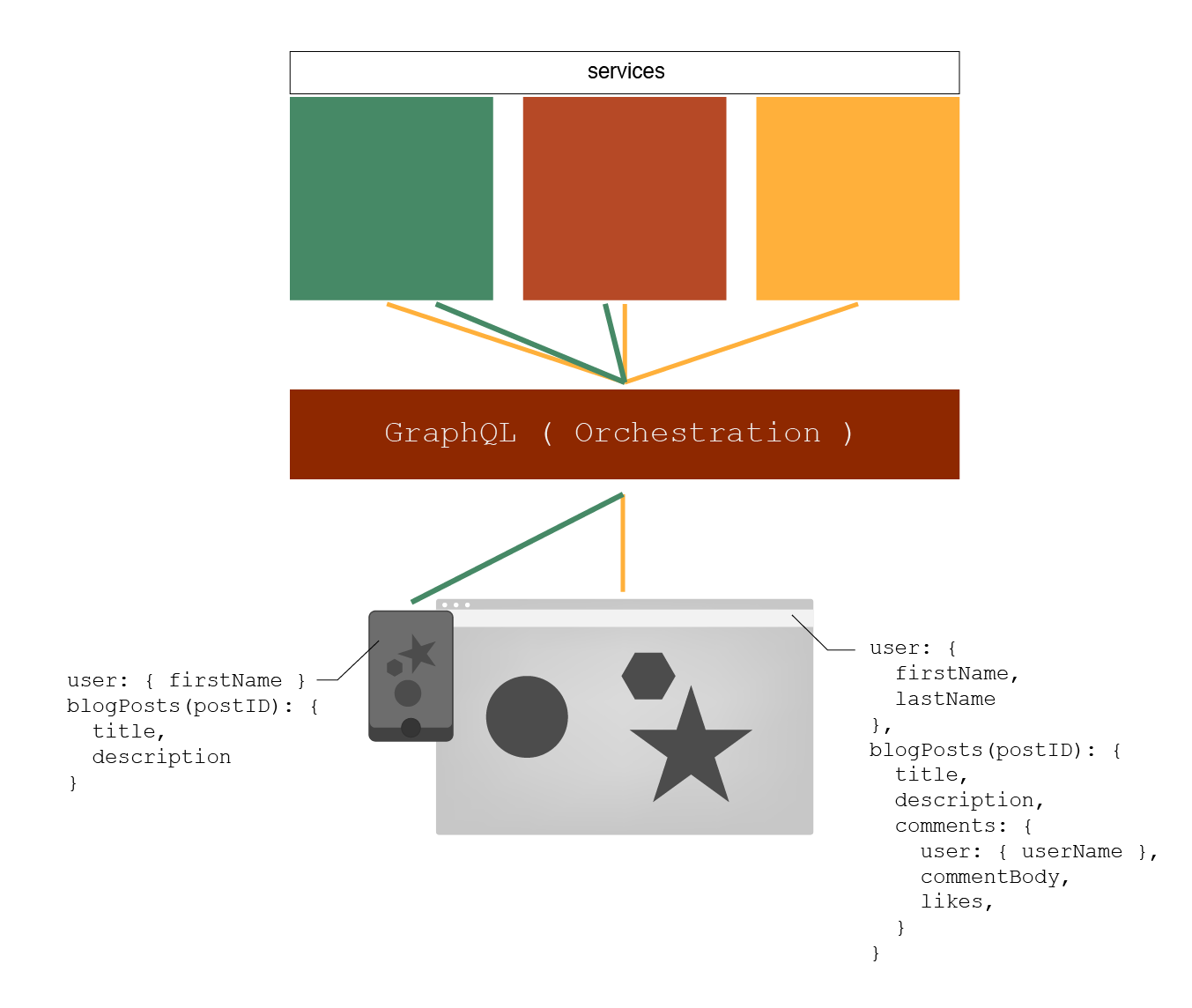
Figure 4 is another simplified architectural perspective as to how clients may request for information and the GraphQL service becomes the fetcher and provider of data. In addition, we are using a bit of pseudo code in the drawing to represent how each client may request information without ever needing to know where exactly that information is sourced. The connected clients will not need to deal with the connection to and failure cases of any one particular service independently, but all at one time.
Figure 5
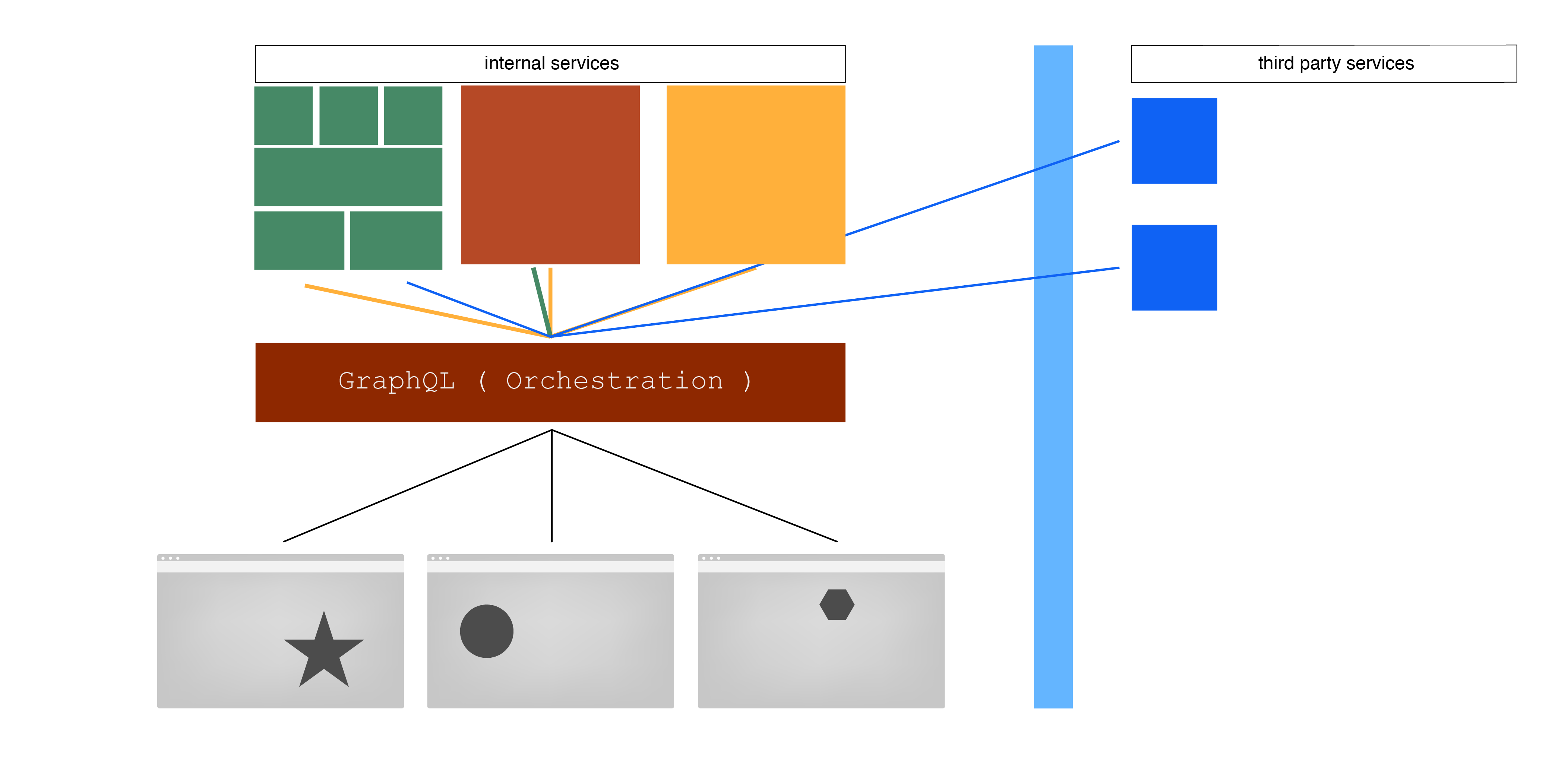
Figure 5 shows us a more mature example of how orchestration fits into our technology stack. We can see services changing from behind the orchestration tier but none of the clients of the orchestration service need to care. More client facing software, or better yet components, are engineered and content is consumed as needed. What is not represented well in this diagram is the fact that not all services need to be called on every request. A powerful pattern that emerges from this architecture is that the content your services provide is only under load as needed by a client or component. This is different in the sense of monoliths doing all of the work all of the time. For instance, say we only wish to know about a user's likes and we already know the user's globally unique identifier, we may not need to put that stress on several services but only one that deals with an individual's likes.
But how do we document this?
The complexity of knowing what an orchestration service may express as content is a daunting one indeed. The good news is though that good solutions have already thought of this. The nature of solutions like GraphQL require that we manually express the how, where and type of information it may provide. By authoring this contract into the service it naturally creates documentation, or the means for creating new documentation, from what was expressed in the rules of how it is to provide content and from where.
If we could imagine the instructions, or blueprint if we dare, an orchestration service understands it may look something like this:
{
user: {
1. get the first name from the users table,
2. get this users city from the address lookup
},
favorites: {
1. find this users likes
2. then look up related content tags
3. look up posts associated with those tags
}
}
Which, with tools like GraphQL may translate into a piece of documentation like:
Figure 6
{
user: {
firstName: STRING,
lastName: STRING,
city: STRING,
favorites: {
likesCount: INT,
technologyTopics: [
{
postTitle: STRING, postContent: VARCHAR,
}
]
}
},
}
These examples are hardly real code at all but the general representation is fairly accurate. From figure 6 we can surmise that there is some structured content there for us to read while never having to understand exactly how it is provided.
Watch out for nails
This post is not intended to convince you or your team to leverage GraphQL or orchestration as a strategy in your architecture. Instead, the goal is to provide a sense of just one way this technology may contribute to creating responsible boundaries in software. Think carefully before considering the adoption of these tools. Long term investment in a decision like this requires that a team keeps up with how it works, deal with keeping it optimized, managing the uptime and much more. GraphQL in the right situation will allow teams and entire companies to stay a more nimble in their ever evolving stack of technology.
Closing thoughts
You may be wondering why? Why do we need to care? The benefit we are working to create is reducing the cost of managing software systems through labor. By reducing the cost of changing a system through means of creating meaningful layers of abstraction and giving work a home.
Introducing systems that manage complexity for us, though incur debt, idealistically reduce the number of individuals, engineers, that require a deeper understanding a complex system in order to use it. Create points of meaningful understanding that serve as a facade to more complex work and keep your teams focused on the goals at hand.
Reduce the costs associated with
-
Creating new work.
-
Replacing or repairing old work.
-
Onboarding engineers.
-
Maintaining and expressing the potential of a system or series of systems.
If you would like to continue this conversation, please feel free to comment below or reach out to me directly through LinkedIn or email.